PPO Algorithm
Proximal Policy Optimization (PPO) is a reinforcement learning algorithm developed by OpenAI in 2017. PPO is designed to optimize the policy function of a reinforcement learning agent, using a surrogate objective function that places a limit on how much the policy can change in each iteration.
PPO uses a neural network to represent the policy function, and it can be used to learn both discrete and continuous action spaces. PPO is known for its robustness, and it has been shown to outperform other state-of-the-art reinforcement learning algorithms in a variety of domains.
Hyperparameters
There are several hyperparameters that can be tuned to get better results with PPO.
- Learning rate (α) - determines how much the policy parameters are updated in each iteration
- Gamma (γ) - Discount factor - determines the importance of future rewards in the policy update
-
Clip parameter (default 0.2)
- The clip parameter controls how much the policy is allowed to change in each iteration. A higher clip parameter can lead to more stable updates, but it can also limit the ability of the policy to explore new actions. A lower clip parameter can lead to more exploration, but it can also lead to instability.
- GAE lambda - a parameter used to compute the Generalized Advantage Estimate (GAE), which is used to estimate the value function (default 0.95)
- Number of epochs per update - determines how many times the data is used to update the policy (default 10)
- Batch size - determines how many samples are used to compute each update (32, 64 or higher)
- Value function coefficient (default 0.5)
- Entropy coefficient (default 0)
Performance metrics
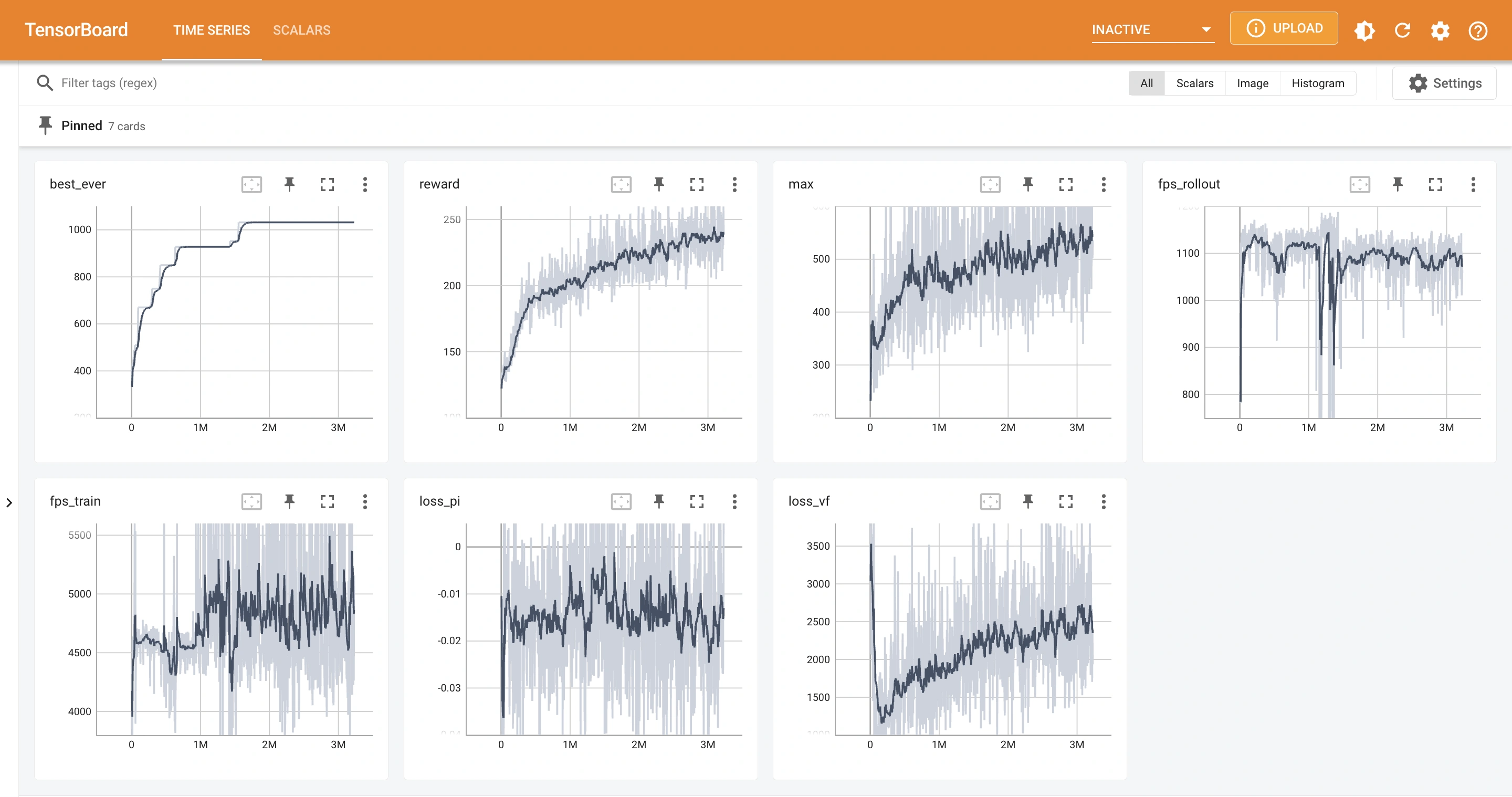
We can use the average reward, policy loss and value loss as metrics to evaluate the performance of a PPO model.
Average reward
Average reward measures the average reward per episode over a certain number of episodes.
Increasing average reward is a sign that model is getting better at the task (better performance). A good range for average reward is task-dependent, and can vary greatly depending on the complexity of the task.
Tips for average reward
Expected average reward is affected by various hyperparameters as well as the reward function.
Here are some common issues with average reward and tips on how to fix them:
1. Average reward too low
- Learning rate (alpha) might be too low. Increase alpha to make the model learn faster.
- Discount factor (gamma) might be too low. Increase gamma to make the model account for more future reward.
- The model might be stuck in a local minimum. Try changing the hyperparameters or reward function to get the model out of the local minimum.
2. Average reward unstable and fluctuates widely
- Learning rate (alpha) might be too high. Decrease alpha to make the model learn slower.
- Discount factor (gamma) might be too high. Decrease gamma to make the model account for less future reward.
- Clip parameter might be too low. Increase clip parameter to prevent the policy from changing too much at once.
Policy loss
Policy loss measures the difference between the old policy and the new policy after an update.
- Policy loss can be positive or negative depending on the advantage of the new policy.
- Policy loss getting closer to zero is a sign that model is becoming more accurate at predictions.
- A perfect model would have a policy loss value of zero, meaning the new policy is identical to the old policy.
- It is normal for policy loss to fluctuate or increase at the start of training, before the policy stabilizes.
Value loss
Value loss measures the difference between the old value function and the new value function after an update.
- Lower value loss is a sign that model is becoming more accurate at predictions.
- A perfect model would have a value loss value of zero, meaning the new value function is identical to the old value function.
- It is normal for value loss to fluctuate or increase at the start of training, before the value function stabilizes.
Examples
PPO can be trained to play many single-player games with either discrete actions or continue actions. Some examples include Tetris, Snake, 2048 and Block Puzzle.
This is a screenshot of tfboard for training PPO to play AI Simulator: Block Puzzle over 3M frames:
Further readings
PPO paper
Detailed explanation of PPO
Interactive demos
Download AI Simulator: Block Puzzle to try using PPO algorithm on the block puzzle:
AI Simulator: Block Puzzle
Classic Block Puzzle Game
Smart AI Auto Play
Idle
AFK Experience